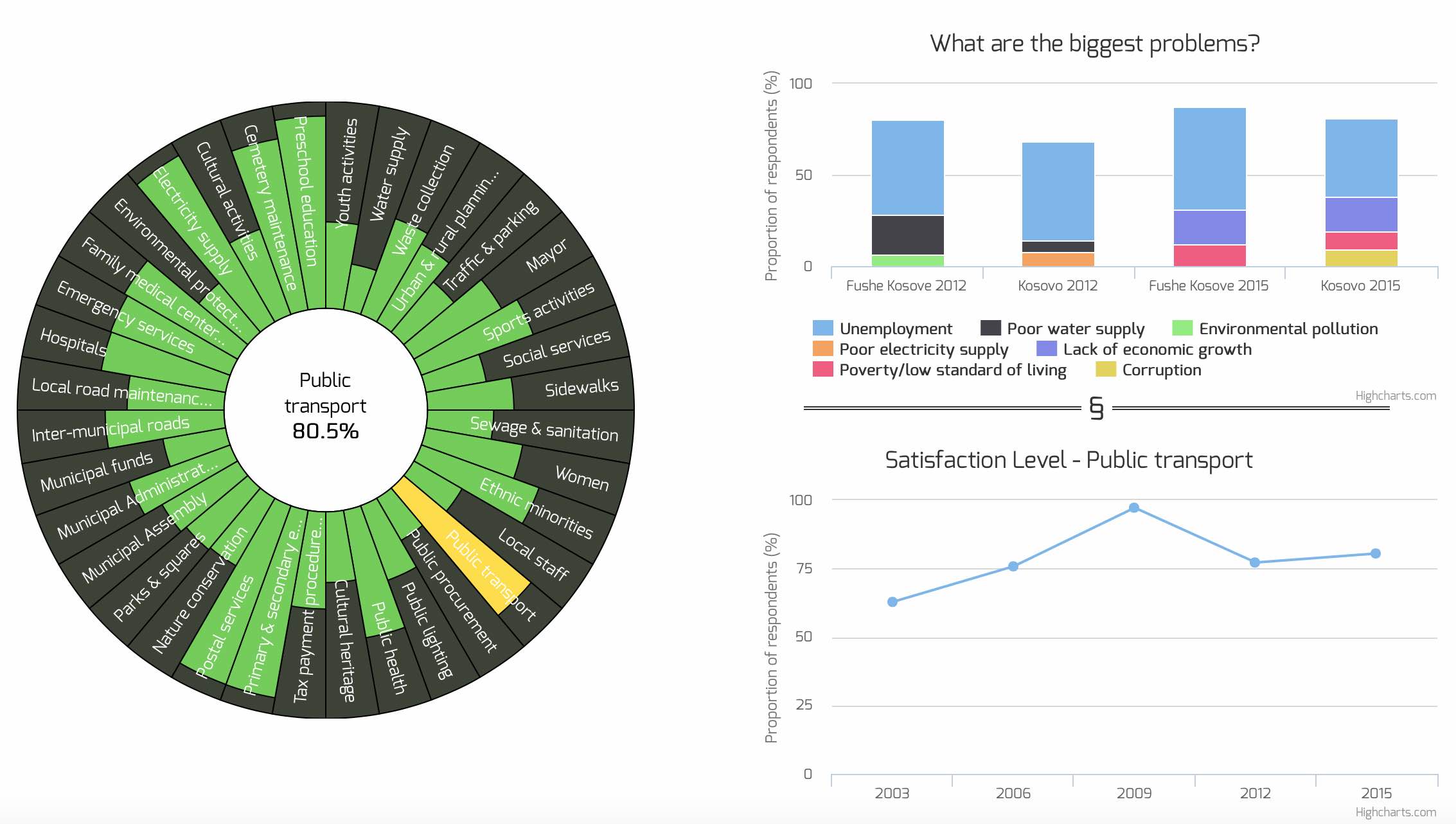
Last week, one of the cooler projects I have worked on since I started with Open Data Kosovo finally got released to the public. The project was to visualize data collected by a survey called Kosovo Mosaic. This survey is run every three years across all 38 municipalities in Kosovo and asks citizens, among other things, how satisfied they are with a range of services the municipality and government provides. 2015 was the fifth installment of the survey.
Continue readingMonth: May 2016

This article is Part VI in a series looking at data science and machine learning by walking through a Kaggle competition. If you have not done so already, you are strongly encouraged to go back and read the earlier parts – (Part I, Part II, Part III, Part IV and Part V).
Continuing on the walkthrough, in this part we build the model that will predict the first booking destination country for each user based on the dataset created in the earlier parts.
Continue reading