
Last week, I covered how setting up a database may not be necessary when creating an app or visualization, even one that relies on data. This week we are going to walk through an example application that runs off data, but does not need a formal database.
First some background. For the last couple of months, I have been attending some basic Arabic classes to help get around Jordan easier. During a recent class, several of the students were discussing the time they had spent putting together physical cardboard flashcards to help them memorize words. Hearing this, and having played around with creating simple applications and visualizations for a couple of years now, it occurred to me that generating flashcards using a simple application would probably be significantly quicker and easier to do. In addition, if done the right way, it could work on your phone, making it available to you anytime you had your phone and an internet connection.
Perhaps as you are reading this, you are thinking that Arabic is a widely spoken language, surely there is already an app for that? And you would be correct, there are multiple apps for learning Arabic. However, the complication with Arabic is that each country/region uses a significantly different version of the language. In addition to these regional dialects, there is Modern Standard Arabic, which is the formal written version of the language. When it comes to the apps currently available, the version of Arabic being presented is almost always Modern Standard Arabic, as opposed to the Levantine Arabic which is spoken throughout Palestine, Jordan, Lebanon and Syria. Additionally, the apps are quite expensive (up to $10), of questionable accuracy/quality, or both.
To address this problem, and for the challenge and learning opportunity, a few weeks back I sat down over a weekend and put together a simple application that would generate Arabic flashcards (you can see the current version here). The application is based on an Excel spreadsheet with translations that I continue to enter over time based on my notes and the class textbook. Using an Excel spreadsheet in this case is advantageous for two key reasons:
- It is simple to edit and update with new translations
- It is a format that almost everyone is familiar with so I can recruit other students and teachers to add translations
With that out of the way, let’s take a look at the high-level process for creating a flashcards app.
1. Collecting the Data
The first step is creating the Excel spreadsheet for our translations. In this case, it is fairly simple and looks something like this:
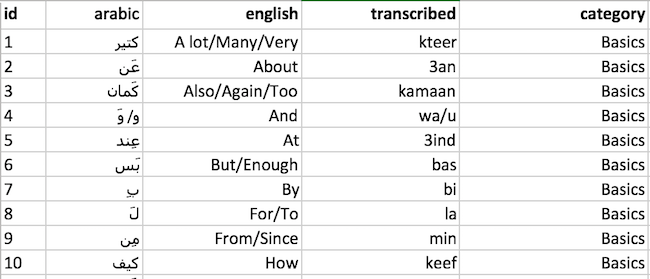
In this spreadsheet, each row represents one word and, through the application, will represent one flashcard. In one column, we have the Arabic script for each word, then in the next column the English translation. In addition, we also have a third version of the word with a column header of ‘transcribed’. This column represents how the Arabic word would look/sound if written in Latin script, something that is commonly used in beginner classes when students cannot yet read Arabic script.[1] Finally, in the last column we have a category column. This will be used to provide a feature where the user can filter the words in the application, allowing them to focus their study on particular sets of words.
A quick note, we also have an ID column, which is not used in the application. It is only included to provide a unique key in our datasets, as good practice.
2. Processing the Data
The next step is to take the data from our spreadsheet, convert it to a format that we can use to generate flashcards in the application, then save it. To do this we will use my favorite Python library, pandas, and the short script shown below.
import pandas as pd
# Read In Data
df = pd.read_excel("./data.xlsx", header=0)
# Create JSON String
json_string = df.to_json(orient="records", force_ascii=False)
json_string = "var data = " + json_string + ";"
# Write to file
text_file = open("data.js", "w")
text_file.write(json_string)
text_file.close()What this script in does is read in the file (in this case, data.xlsx) to a pandas dataframe (line 5). After that (line 8), we use the to_json method to output the contents of the dataframe to a JSON string. In line 9 we add some JavaScript to the beginning and end of that JSON string, then in lines 12-14 we save the string as a JavaScript file, data.js.
There are a couple of important things to note here. The first is that when dealing with non-Latin text characters (like Arabic characters), we need to specify that force_ascii=False (the default value is True). If we don’t do this, the script will return an error and/or convert the Arabic letters into a combination of Latin characters representing the Unicode character (i.e. it will look like gibberish).
The second thing to note for those that have not worked with JSON, or key-value stores more generally, is that this is the format that most data comes in when used in programs and applications. It is a highly flexible structure and, as a result, there are many ways we could represent the data shown above. In this case, we are using the ‘records’ format (as specified by pandas), which will look like this:
[
{
"id":1,
"arabic":"كتير",
"english":"A lot\/Many\/Very",
"transcribed":"kteer",
"category":"Basics"
},
{
"id":2,
"arabic":"عَن",
"english":"About",
"transcribed":"3an",
"category":"Basics"
},…
]If this isn’t making any sense, or you would like to see some of the other possibilities, copy and paste some spreadsheet data into this CSV to JSON convertor. Toggling a few options, it should quickly become obvious how many different ways a given dataset can be represented in JSON format.
3. Building the App
Now that the data is ready, we create the files needed for the flashcards application. In this case, it is only three files, a HTML document (index.html) for the page, a CSS file for the styling, and an additional JavaScript file that will use the data in data.js to create the flashcards and generate the various features of the application. For those that are interested in the full code or want to create your own version, please feel free to checkout/fork the GitHub repo. For those that do not want to get too far into the weeds, there are just a few things I want to highlight about what the code is doing.
Firstly, the filtering and language options in the application are being generated directly from the data. What this means is that as more categories are added to the Excel spreadsheet, or if the languages change (i.e. the headings in the spreadsheet change), as soon as I update the underlying Excel and run the script shown above, all the options in the application will also update accordingly.
Secondly, I added a feature that allows the user to keep score. It is a simple honesty-based system, but I found it does provide some motivation to keep improving, as well as removing an element of self-deception as to how well you are actually doing. Often I would find myself thinking that I was getting almost all of them correct, only to find my correct percentage hovering around 70%.
Finally, a note on randomness. Whether the user is going through the cards unfiltered, or filtering for some category, the application is displaying the flashcards in a random[2] order. This random selection algorithm went through several iterations:
- In version 1, the algorithm would simply select four (the number of flashcards presented to the user at one time) random selections from the pool of eligible words.
- Upon testing version 1, it was found that, with surprising regularity, the same word would be selected more than once in a group of four flashcards. To address this, in version 2 a condition was added that when randomly selecting a word, it would only be accepted if that word had not already been selected in the given pool of four words.
- On further testing, I noticed another annoying issue. As I continually refreshed the four flashcards being displayed, some words would show up repeatedly, while others would take forever to show up, or not show up at all. To avoid this, for version 3, I changed the algorithm again. Now, instead of selecting four words at random, the algorithm instead took the whole list of words, shuffled them in a random order, and ran through the list in the new shuffled order. When the list ran out of words, it took the full list, shuffled it again, and continued.
- This was a big improvement. As I refreshed, I got different words, and was able to see all the words before they started repeating. But then I found another issue. In cases where the number of eligible words was not divisible by four, the old shuffled list and the new shuffled list would overlap in a selection of four words. In these cases, there was a possibility that the same word would be repeated. This is a little difficult to visualize, so the illustration below tries to present what was happening using an example list of ten words:
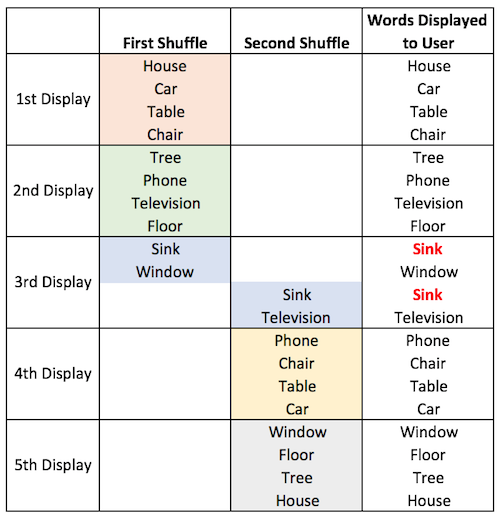
To address this, in version 4, a new condition was added. In cases like the example shown above, the algorithm will check the words from the new shuffled list to ensure they are not already selected from the old list. If a word is already selected, it will move that word to the end of the list and instead take the next word on the list. Here is another diagram to show what is happening:
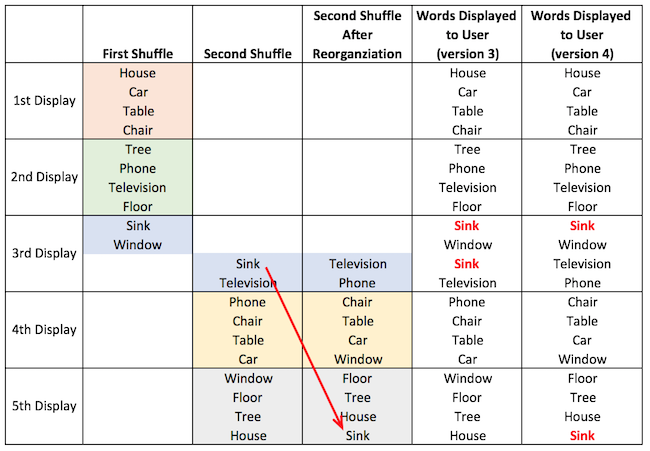
4. Finishing Up
Ok, for those stepping through this and creating your own flashcards app, at this point you have copied the code available from the repo, made any changes to the spreadsheet, and rerun the script to refresh the data. For the final step, there are a couple of things that can be done.
If you are only planning to use the app on the same computer as you are using to create the flashcards app, you are done! Just open the index.html file using Chrome, Firefox or Safari (you can try Internet Explorer, but you know…) and you can test and use the app as you would use any website.
If you want to publish your flashcards app online to share with others, by far the easiest way is to use a service such as GitHub pages. I don’t want to turn this into a beginners guide to using git and GitHub, but there is excellent documentation available to help get you started if you would like to do this. You can see my version at the following address: https://vladimiriii.github.io/arabic-flashcards/, but there is even an option to redirect it to a domain of your choosing should you have one.
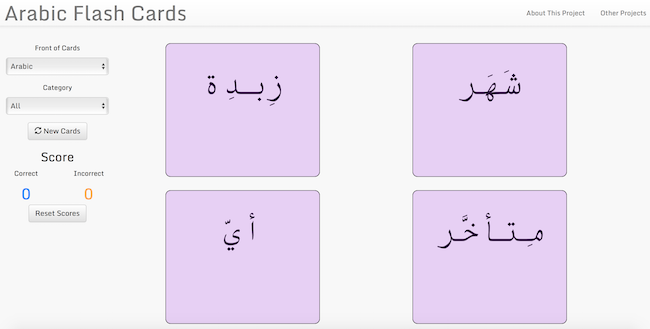
I hope this was a helpful guide to how a simple application can be created without a database, even if the application runs on some underlying form of data. Let me know what you think in the comments below!
[1] Because Arabic has many sounds that are difficult to convey in Latin script, this is also why when Arabic is transcribed, you will often find multiple spellings of the same word (e.g. Al-Qaeda vs Al-Qaida).
[2] As will be discussed in a new piece to be written, it is not truly random, and the reasons why are pretty interesting.
so i wanna make the flash card app like yours but can i use excel to add pictures instead of words and if so what code do i need to add to it . also i cannot find the css of the flashcard app they are blank pages
Thanks for posting this example. I have copied your repo but when I created my own data.js file by reading my data.xlsx file I only get one card with Arabic. The other three cards are blank. You can see here: https://learnyourdeen.info/flashcards/test/
I merely copied my data into your .xlsx file, maintaining the same formatting, columns, etc.
Sorry, should have put my repo here for you to look at: https://github.com/marcmanley/arabic-flash-cards
I’ve been looking for something like this. My question, however, is providing that we list designations of cards by usage (so, how many times a word might be used in a text), can you store the number of times right, number of times wrong, last time right, and last time wrong, so that you can choose based on categories like “Word used between 120-150 times + all words missed in the last month” or something like that?
Oops, here’s another example. All words between 120-150 times that I missed in the last month. Or, the same set missed three times out of the last thirty. This way, I and others can focus on words with which we are struggling rather than rehearsing words we already know over and over.