
This article is part of a series of practical guides for using the Python data processing library pandas. To see view all the available parts, click here.
One of the most fundamental concepts in data science and data work in general is joining two tables together based on some shared column or index. In SQL it is a JOIN. In Excel it is INDEX-MATCH or VLOOKUP. In pandas, two methods are available to join tables together: merge and join. We will look at both of those methods in this guide.
An important note before we go on: this guide is not going to go into the details of how joins work or what the difference is between an INNER JOIN, LEFT JOIN and FULL OUTER JOIN. The examples we will use are pretty simple and you will hopefully still be able to follow along, but if this concept is completely new to you, you might want to read up on it first and come back.
Reading in a dataset
If you don’t have a dataset you want to play around with, University of California Irvine has an excellent online repository of datasets that you can play with. For this explainer we are going to be using some fictional data about a company. If you want to follow along, you can create the DataFrames using the code below. If you want to better understand how this code makes DataFrames, I recommend reading our importing JSON data guide:
import pandas as pd
df_employee = pd.DataFrame({
"first_name": ["John", "Peter", "Sam", "Paula", "Carla", "Nat", "Jimeoin"],
"last_name": ["Johnson", "Peterson", "Samuelson", "Paulason", "Carlason", "Natson", ""],
"department": ["A", "B", "C", "A", "A", "C", "D"],
"title": ["SA", "VP", "A", "SA", "VP", "A", "CEO"]
})
df_department = pd.DataFrame({
"department": ["A", "B", "C", "D"],
"dept_name": ["Accounting", "HR", "Sales", "Management"],
"Floor": [21, 22, 23, 47]
})
df_title = pd.DataFrame({
"acronym": ["A", "SA", "VP", "CEO"],
"title": ["Associate", "Senior Associate", "Vice President", "The Big Boss"],
"base_salary": [70000, 90000, 110000, 1]
})merge
merge is a method of the DataFrame class that allows us to join two DataFrames. Being a method means we call it directly on the DataFrame we want to join from using df.merge(), and that DataFrame will become the left table in the join. We then pass several parameters to the merge method:
right: the DataFrame we want to join to, i.e. the right table in the join.how: The type of join we want to use. Can beinner,left,right,outerorcross.- The join condition: There are several parameters we can use to specify which columns or indices to use to complete the join:
on: If you are joining using columns, and those columns have the same names in both DataFrames, you can provide the name of that column (or a list of names if there are more than one) to theonparameter. If you are familiar with SQL, think of this as the equivalent of theUSINGclause.left_on/right_on: If the columns you are joining on have different names, you can provide the names of those columns to theleft_onandright_onparameters. Again if you are joining on more than one column you can provide lists of column names to these parameters, and they will be matched based on the order provided. Think of this as the equivalent of theONclause in SQL.left_index/right_index: If you want to join on the index of the DataFrame, we can pass “True” to theleft_indexand/orright_indexparameters.- Note that you can also mix and match
left_on/right_onwithleft_index/right_index. For example, you could specify to join on a column from the left table (left_on="A") and the index for the right table (right_index=True).
There’s a lot to take in there, so let’s look at some examples to hopefully clarify what we are talking about. First the simplest case, everything is nice and clean and the columns we want to join on have the same names:
df_employee.merge(df_department, how='inner', on="department")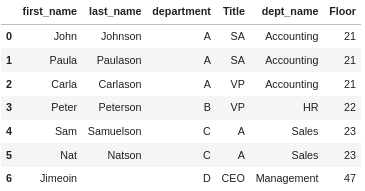
Now, we can also use left_on and right_on to achieve the same join even if they have the same name, just to show how it works:
df_employee.merge(df_department, how='inner', left_on="department", right_on="department")Now let’s set the department column as an index in df_department, and then use the right_index parameter to do the same join again:
df_department.set_index("department", inplace=True)
df_employee.merge(df_department, how='inner', left_on="department", right_index=True)Non-joining columns with the same names
Sometimes when you are joining tables, there are columns that you are not joining on that have the same name in both tables. As a result, your output DataFrame would end up with two columns with the same name, which is a bit of a problem. To handle this, by default pandas will rename both columns by adding “_x” to the end of the left DataFrame column name, and “_y” to the end of the right DataFrame column_name.
These suffixes serve the basic purpose of differentiating the columns, but don’t tell us very much. However, we do have the option to specify our own column suffixes with the suffixes parameter. By passing it a tuple with the following format:
suffixes=("_add_to_left_column_name", "_add_to_right_column_name")You can also pass None as one of the values if you want one column to retain the original name. Let’s take a look at an example. Let’s join df_employees to df_title. Note that our overworked and perhaps slightly incompetent DB admin has created two problems for us:
- The column we want to join to in
df_title(acronym) has a different name to the corresponding column indf_employeetable (title). - There is another column in
df_titlethat has the nametitlebut it has different information to thetitlecolumn indf_employees.
Let’s first see what happens when we don’t supply the suffixes parameter:
df_employee.merge(df_title, how='inner', left_on="title", right_on="acronym")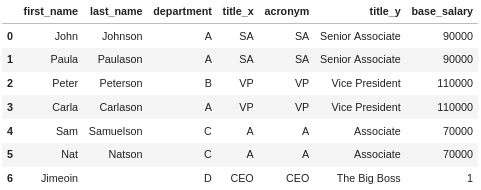
OK, it works, but we end up with these columns title_x and title_y. Let’s try again with a suffixes parameter:
df_employee.merge(df_title, how='inner', left_on="title", right_on="acronym", suffixes=(None, "_full"))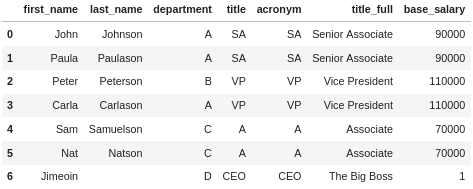
That looks better, we now have column names that tell us something, but we still have two columns with the same information, title and acronym. In this case there isn’t much we can do with merge to avoid that, but we can use drop to remove the duplicate column if we want.
join
join works much the same as merge, but has a more specific use case – join is designed to join on the index only. There are options for joining on specific levels of a MultiIndex, but not for joining on columns. When the column(s) you want to join on are already in the index of the two DataFrames, then join is a more concise version of merge:
# Recall we already set the "department" column as the index
# for df_department. Now we do the same for df_employee.
df_employee.set_index("department", inplace=True)
df_employee.join(df_department, how='inner')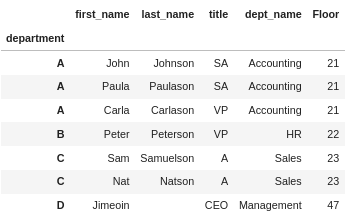
The way join handles suffixes when there are columns with the same names is a little different from merge as well. Instead of one suffixes parameter where we pass two values, now we have a lsuffix and a rsuffix parameter to pass one suffix each.
join is obviously a much more specific function than merge and as a result, I expect you will end up using merge significantly more than you use join. However, for the specific case where you want to join on the indices of both DataFrames, join is going to save you from having to type out “left_index=True, right_index=True“. Whether this matters enough for you to switch up and use join in those cases is going to be entirely dependent on you.
Wrapping Up
In this guide we looked at two ways we can join tables in pandas. merge is the method of choice in most circumstances, allowing us to specify which columns or indices to join on, what type of join to use (INNER, LEFT, etc), and how to handle cases when we have non-joining columns with the same name in both tables.
join is the other option for joining tables, but is a more specific method for cases when the columns to join on are already in the index of both DataFrames. In that specific case, join is a more concise version of merge.
0 Comments
1 Pingback