
This article is part of a series of practical guides for using the Python data processing library pandas. To see view all the available parts, click here.
In this guide we are going to look at three ways to handle a scenario where you want to update the values in a column based on whether some condition is true or not. This condition could be applied based on the same column you want to update, a different column, or a combination of columns.
The three methods (or two methods and a function we will look at are:
where– a method of the pandas.DataFrame class.mask– a method of the pandas.DataFrame class and inverse ofwherenumpy.where– a function in the numpy library.
Reading in a dataset
If you don’t have a dataset you want to play around with, University of California Irvine has an excellent online repository of datasets that you can play with. For this explainer we are going to be using the Wine Quality dataset. If you want to follow along, you can import the dataset as follows:
import pandas as pd
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep=';')The where method
The where method is a method that becomes useful when we want to update the values in a column based on whether a condition is True. For example, in our sample dataset, if let’s say we wanted to update the quality rating of the wine if the value in the alcohol column (assumed to be alcohol by volume) is over 10%. We are worried about the wine being too strong so we want to update the quality to 0 so we don’t accidentally select one of these wines. As per the filtering and segmenting guide we could do something like this:
df.loc[df["alcohol"] >= 10, "quality"] = 0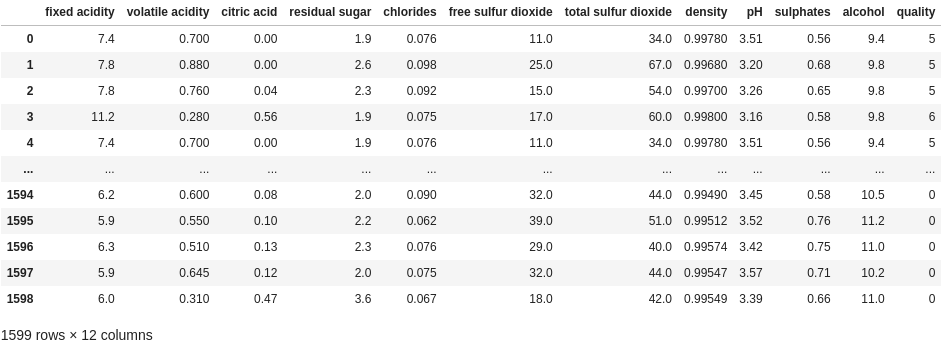
This works, but the problem is that we overwrite our original data. That means we would first have to copy the original column, then run this line on the new column.
The alternative is to use where:
df["quality_updated"] = df["quality"].where(df["alcohol"] < 10, 0)
df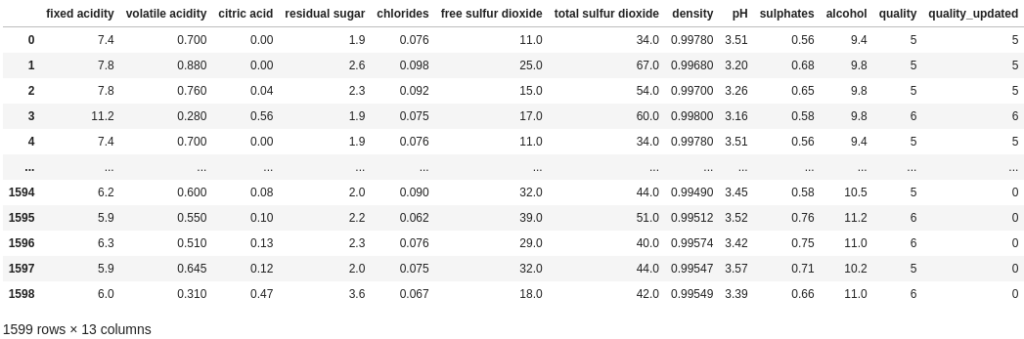
The slightly unintuitive aspect of where, at least for me, is that it updates the rows that do not satisfy the condition, i.e. those that evaluate to False. Accordingly, we have to reverse our condition to df['alcohol'] < 10.
The mask method
The mask method is the reverse of where. It is the same concept but now it updates the rows that satisfy the condition, i.e. the rows that evaluate to True. For me this makes more sense as we are targeting the rows that we want to update. Reproducing the code from above:
df["quality_updated"] = df["quality"].mask(df["alcohol"] >= 10, 0)
dfnumpy where function
An alternative to both of the above, which has actually been my preference for a while now is the numpy version of where. For those that aren’t aware, numpy is actually a dependency of pandas, so anywhere you have pandas you should have numpy available. As per the where and mask methods, numpy.where intakes a condition as the first parameter, but then has two parameters, a value if true parameter and a value if false parameter. Let’s take a look at an example that simply reproduces what we were doing above:
df["quality_updated"] = np.where(df["alcohol"] >= 10, 0, df["quality"])
dfSo in this example, it becomes slightly less concise than the earlier examples because we have to explicitly state the alternative value. But this can often end up being an advantage when we don’t want to keep the original values. Consider the following example:
import numpy as np
df["sugar_level"] = np.where(df["residual sugar"] > 2, "Sweet", "Dry")
df[["residual sugar", "sugar_level"]]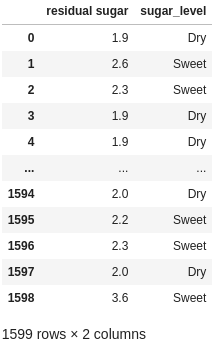
In this case we have defined a new categorical column with two values based on the residual sugar column. Are there other ways this could be done? Definitely. But are any going to be as clear to a reader as to what your intention is?
Stepping it up
In the cases above we have used very simple conditions to update values. But as was covered in the advanced booleans guide, there is nothing to prevent us from getting more complicated and creating a conditional based on multiple columns. Additionally, we don’t have to provide static values as the true and false values, we can use other columns, or even calculations using other columns.
For example, let’s say we are planning are dinner party and we want to select some wines. But we are fussy and we have several requirements. We don’t like sweet wine, so want to penalize wines that have too much residual sugar. We don’t like strong wines so we want to penalize wines that have too much alcohol.
In this case, for the sake of readability, we separate out the condition into a separate line and save it to a variable called mask, then provide mask as a parameter to numpy.where:
sugar_cutoff = 4
alcohol_cutoff = 10
mask = ((df["residual sugar"] < sugar_cutoff) & (df["alcohol"] < alcohol_cutoff))
penalty = 0.75
df["quality_updated"] = np.where(mask, df["quality"], df["quality"] * penalty)
df[["residual sugar", "alcohol", "quality", "quality_updated"]].sort_values("quality_updated", ascending=False).head(20)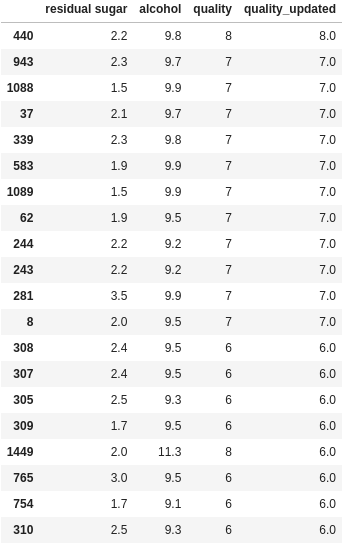
Wrapping Up
In this guide we covered several ways to update and/or create new columns by applying if/else logic to an existing column (or columns) in a DataFrame. We looked at the where and mask DataFrame methods, as well as the numpy.where function, all of which are have slightly different approaches to the same problem. Finally, although these methods can seem simple, we saw how they can be stepped up very quickly to apply complicated logic in a clear and concise way.