
This article is part of a series of practical guides for using the Python data processing library pandas. To see view all the available parts, click here.
In this guide we will look at a few methods we can use to add pandas DataFrames together vertically, stacking them one on top of the other. This will include two pandas methods concat and append, and a third way where we make use of some simple python methods. This last method can often be much faster than working with DataFrames directly, especially if we want to repeatedly append one row at a time to a DataFrame.
If you are looking at joining tables, or adding two tables together horizontally, try the guide on joining tables.
Reading in a dataset
If you don’t have a dataset you want to play around with, University of California Irvine has an excellent online repository of datasets that you can play with. For this explainer we are going to be using some fictional data that represent employees from two companies “abc” and “xyz”. If you want to follow along, you can create the DataFrames using the code below. If you want to better understand how this code makes DataFrames, I recommend reading our importing JSON data guide:
import pandas as pd
df_employee_abc = pd.DataFrame({
"first_name": ["John", "Peter", "Sam", "Paula", "Carla", "Nat", "Jimeoin"],
"last_name": ["Johnson", "Peterson", "Samuelson", "Paulason", "Carlason", "Natson", ""],
"department": ["A", "B", "C", "A", "A", "C", "D"],
"title": ["SA", "VP", "A", "SA", "VP", "A", "CEO"],
"age": [40, 32, 65, 26, 54, 21, 29]
})
df_employee_xyz = pd.DataFrame({
"first_name": ["Juan", "Pedro", "Andres", "Roberta", "Cristina", "Laura", "Julio"],
"last_name": ["Rodriguez", "Garcia", "Hernandez", "Cazorla", "Etxeberria", "Marcos", ""],
"department": ["A", "B", "C", "A", "A", "C", "D"],
"title": ["SA", "VP", "A", "SA", "VP", "A", "CEO"],
"height": [178, 165, 189, 178, 175, 161, 190]
})concat method
The primary method that should come to mind when you want to stack two DataFrames on top of each other is concat. concat allows us to stack two DataFrames, and also gives us a bunch of options to handle various scenarios. But let’s take a look at the most basic case first:
pd.concat([df_employee_abc, df_employee_xyz])
As can be seen, this is pretty straight forward. It puts one DataFrame on top of the other. But let’s make a few observations.
Firstly, it doesn’t matter what order the columns in our DataFrame are, concat will match them up by the column name when it appends them together.
Secondly, if one column exists in one DataFrame but not the other concat will default to including the unmatched columns in the results. In this case, it will fill in “NaN” for the rows from the DataFrame which didn’t have that column. We can see this in the age and height columns.
If you don’t want to include unmatched columns, we can set the join parameter to “inner”, which will ensure we only keep the columns that existed in both DataFrames.
pd.concat([df_employee_abc, df_employee_xyz], join="inner")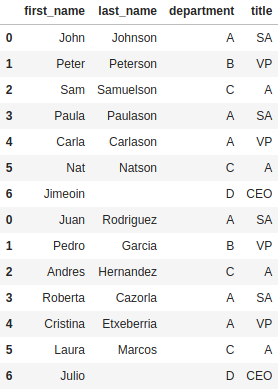
Next, you will note that appending the DataFrames will keep the indices from the original DataFrames. In our cases this means we end up with duplicate indices. We can instead tell concat to reset the index in the result DataFrame by setting the ignore_index parameter to True.
pd.concat([df_employee_abc, df_employee_xyz], join="inner", ignore_index=True)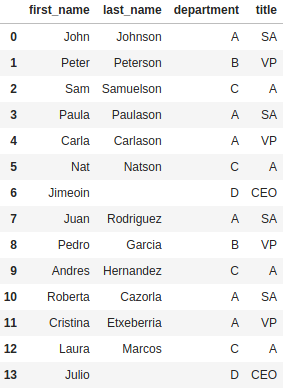
Finally, what if we want to keep track of which DataFrame each row originally came from? That is, what company each employee come from. This is where we can use the keys and names parameters:
pd.concat([df_employee_abc, df_employee_xyz], join="inner", keys=["ABC LLP", "XYZ LLP"], names=["company", "ID"])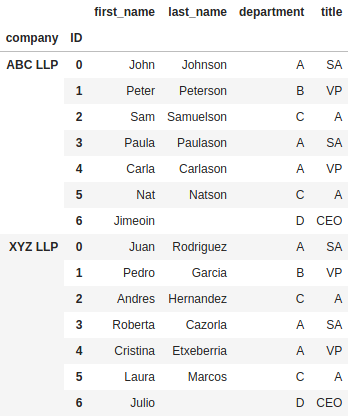
If you want these values as just regular columns, you can also chain on .reset_index() to the end of the previous line.
Special Case: Appending Horizontally
You might notice from the official documentation that one of the parameters for concat is axis. By default this will be set to 0, which means concat will append along the index axis. In other words, it appends the rows vertically as we have seen above. However, there is a case where we might want to append horizontally.
“Wait Brett, you devilishly handsome data nerd, isn’t that just a join?” I hear you say. Well, it is… sort of. In the same way that concat will match up the columns by name when it appends DataFrames vertically, it will try to match up rows by the row index when it appends horizontally.
pd.concat([df_employee_abc, df_employee_xyz], axis=1)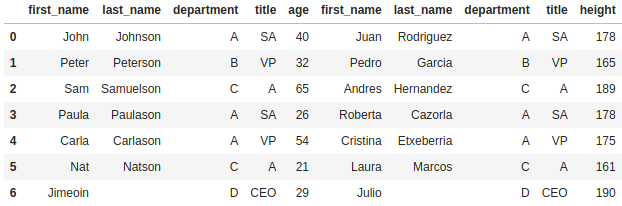
However, unlike when you merge or join, concat wants the indices in both DataFrames to contain unique values. If either DataFrame contains non-unique values, there are a couple of possible outcomes.
If both DataFrames have the same number of rows and the indices are exactly the same in both DataFrames, concat will append the DataFrames, row for row, even if there are duplicate values in the index.
If either of the two conditions above are not met (same number of rows, exactly the same index) concat will throw an InvalidIndexError: Reindexing only valid with uniquely valued Index objects.
In any case, it is strongly recommended that you use merge or join to append horizontally as they have much clearer expected behaviors when there are duplicate values and/or the rows are in different orders.
append method
As join is to merge for joining tables, append is the more specific, streamlined version of concat for appending DataFrames, at the cost of some functionality. append is also a method of the DataFrame class, rather than a separate function like concat, which means we use it slightly differently:
df_employee_abc.append(df_employee_xyz)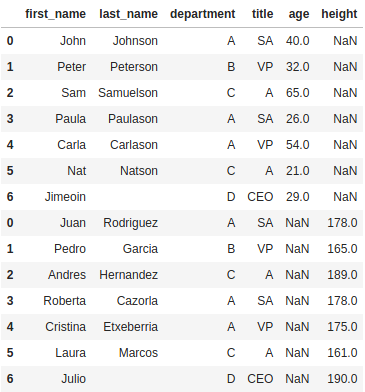
As mentioned, append does not have as many options as concat. We do have an ignore_index parameter, but there is no join parameter, append will always do an outer join. There is no option for keys to keep track of which DataFrame the data come from, you will have to add a column to each DataFrame with a value to track which row came from which DataFrame.
Appending 1 row at a time
Occasionally there will arise a scenario where we need to repeatedly add one row at a time to a DataFrame. The problem is, using the methods above will be painfully slow if you have to repeat this process any reasonable number of times.
For example, this code appending 1000 rows to a DataFrame, one row at a time, takes around a full second to complete.
df_test_1 = df_employee_abc.copy()
for i in range(1000):
row = [{"first_name": f"{i} first",
"last_name": f"{i} last",
"department": "New",
"title": "A",
"age": i }]
df_test_1 = df_test_1.append(row, ignore_index=True)To speed this up, we can take advantage of the underlying structures that make a pandas DataFrame. Adding rows to a DataFrame – slow and clunky. Adding items to a list – easy and fast. Given a DataFrame is essentially a dressed up list of lists we can take advantage of this. Modifying our code from above, we can first add the rows to a list and then append all the new rows at once at the end:
df_test_2 = df_employee_abc.copy()
new_rows = []
for i in range(1000):
new_rows.append({"first_name": f"{i} first",
"last_name": f"{i} last",
"department": "New",
"title": "A",
"age": i })
df_test_2 = df_test_2.append(new_rows, ignore_index=True)This version of the code takes 2ms (0.002 seconds) to complete, a roughly 500x increase in speed.
Wrapping Up
In this guide we looked at ways to append DataFrames together. There are two main methods we can use, concat and append. concat is the more flexible way to append two DataFrames, with options for specifying what to do with unmatched columns, adding keys, and appending horizontally. append is a more streamlined method, but is missing many of the options that concat has.
Finally, we looked at the special case of adding one row at a time repeatedly. In that case, both concat and append are very slow and it is better to append rows to a list, then append the all the rows in one step.
Leave a Reply